InfiniBench
A Benchmark for Large Multi-Modal Models
in Long-Form Movies & TV
Shows
🎉 Accepted at EMNLP 2025 🎉
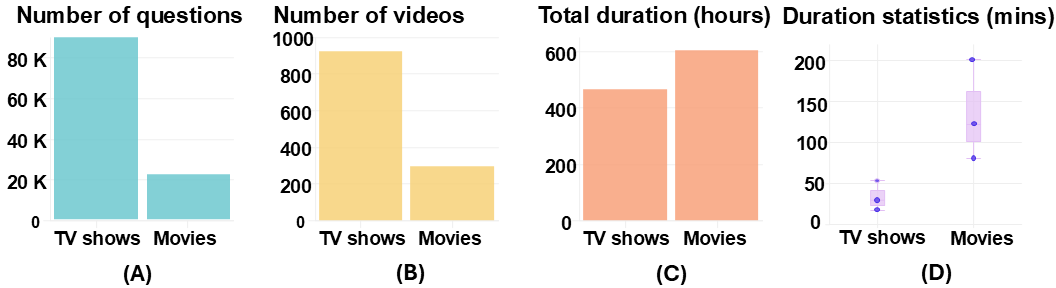
Rigorously evaluating the capabilities of multimodal models across 8 key skills with over 1,000 hours of video content
◆ King Abdullah University of Science and Technology
(KAUST)
◆ Monash University
◆ RICE University
* Equal contribution
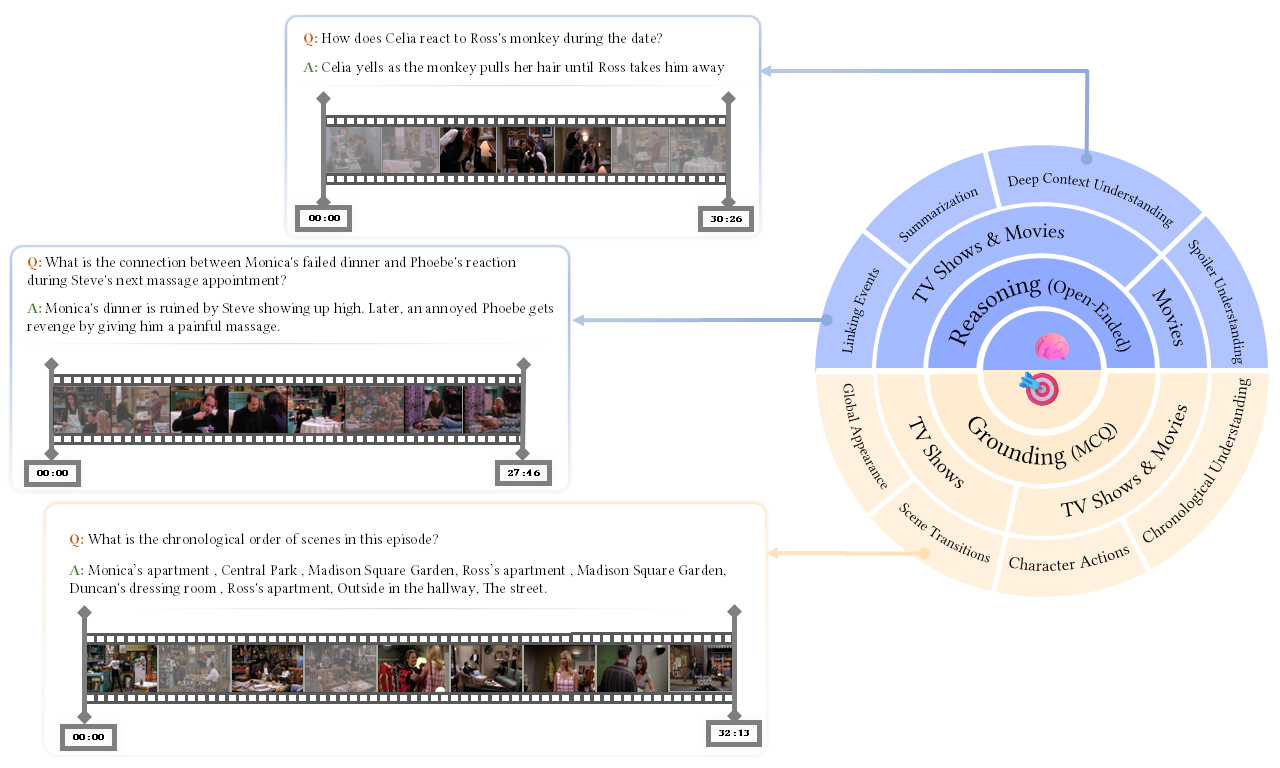
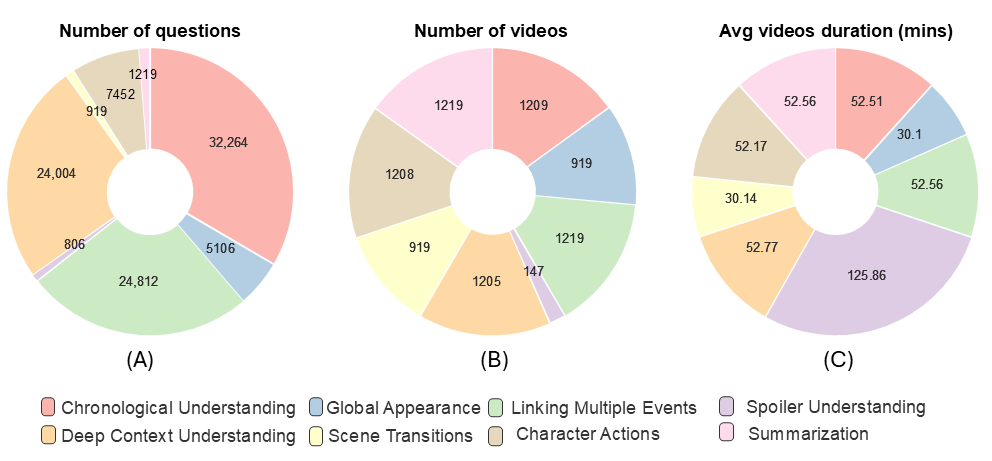
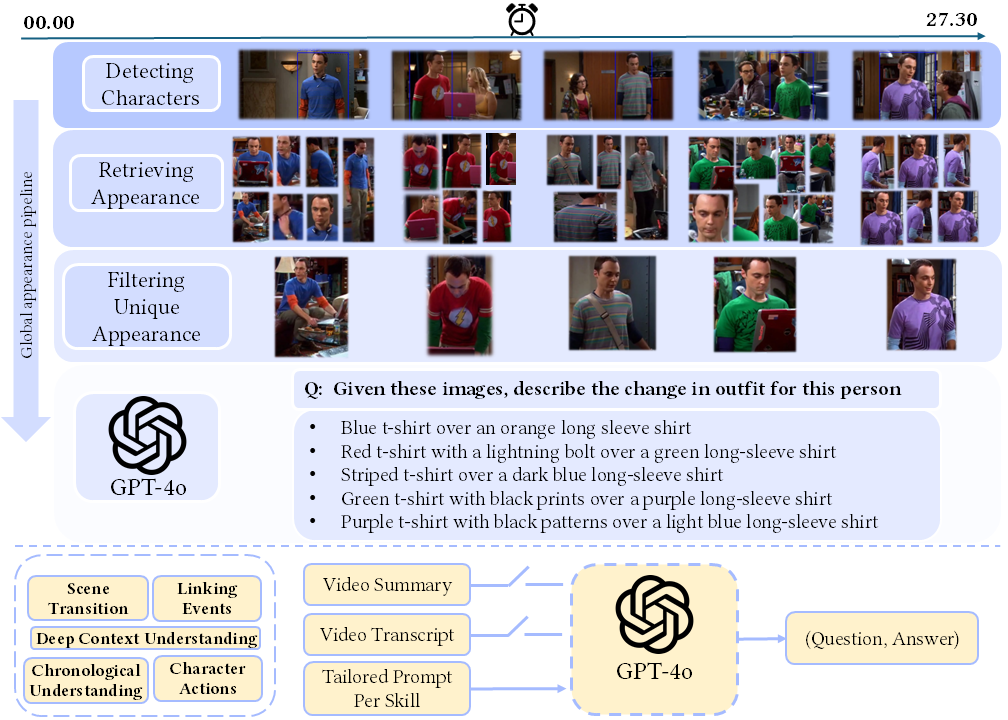
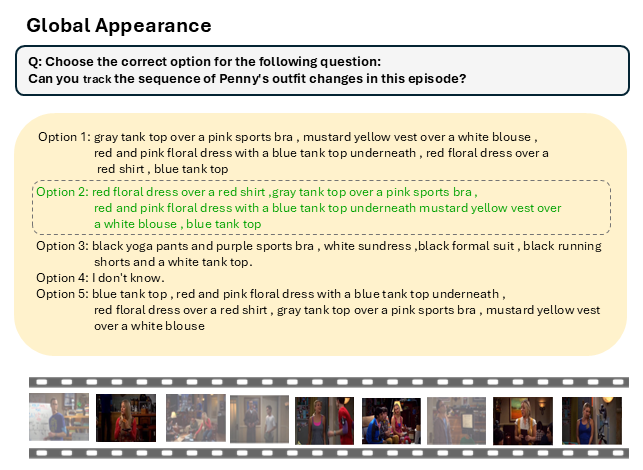
InfiniBench skill set comprising eight skills. The right side represents skill categories and question types, while the left side provides examples of both multiple-choice (MCQ) and open-ended questions.